
今回の内容
今回は、sort・uniqコマンドについて解説します。
sort
テキストファイルをソートするには、「sort」コマンドを使用します。

| コマンド | |
|---|---|
| 意味 | 行単位でファイルの内容をソートする。 |
| 書式 | sort [オプション] [+開始位置 [-終了位置]] [ファイル名] |
| オプション | 説明 |
| -b | 行頭が空白ならば、無視。 |
| -f | 大文字と小文字の区別なくソート。 |
| -r | 降順にソート。 |
| -t | 指定したを区切り文字としてフィールドを認識。 |
| -n | 数字を文字でなく数値として処理。 |
| -k | ソート対象としてn番目のフィールドを指定。 |
——————–
サンプルファイルの作成
viコマンドで「sample1.txt」を作成
[root@localhost ~]# vi sample1.txt [root@localhost ~]# cat sample1.txt 2 BBR 1 AAA 11 CCC 12 DDDD 31 ABCDEF ★スペースで作成 [root@localhost ~]#
——————–
例)ソートして表示
「sample1.txt」をソートして表示。
[root@localhost ~]# sort sample1.txt 2 BBB 1 AAA 11 CCC 12 DDDD 31 ABCDEF [root@localhost ~]#
——————–
例)ソートして表示(数字を文字ではなく数値として処理)
「sample1.txt」をソートして表示。(数字を文字ではなく数値として処理)
[root@localhost ~]# sort -n sample1.txt 1 AAA 2 BBR 11 CCC 12 DDDD 31 ABCDEF [root@localhost ~]#
——————–
例)ソートして表示。(行頭が空白なら無視して処理)
「sample1.txt」をソートして表示。(行頭が空白なら無視して処理)
[root@localhost ~]# sort -b sample1.txt 1 AAA 11 CCC 12 DDDD 2 BBR 31 ABCDEF [root@localhost ~]#
——————–
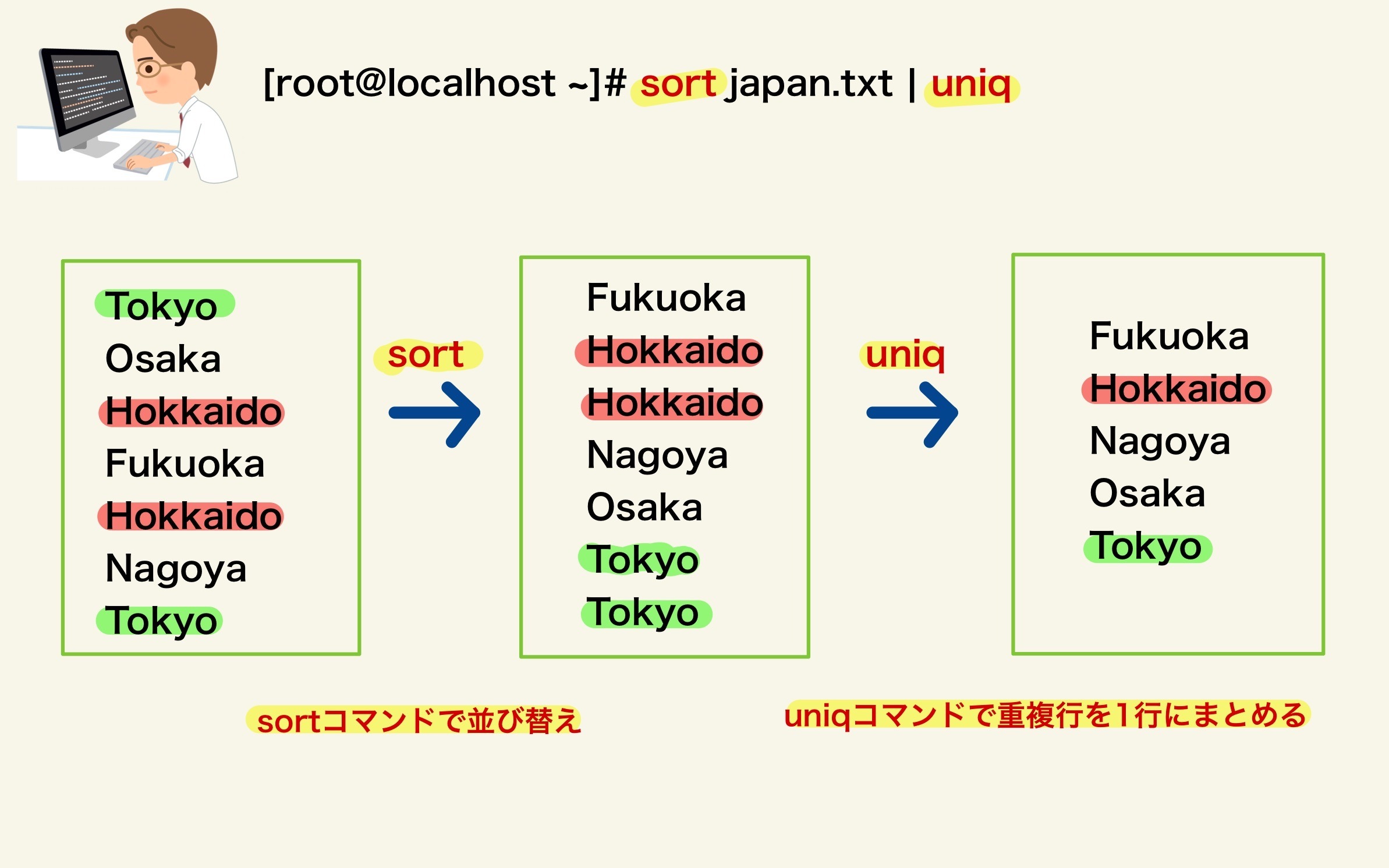
uniqコマンド
ソート済みのファイルから重複した行を削除には、「uniq」コマンドを使用します。
本来、「uniq」コマンドは、連続して重複している行を1行にまとめて表示するコマンドなの
で、「sort」コマンドなどで、並べ替えてから使用されることが多いです。
| コマンド | |
|---|---|
| 意味 | 入力されたテキストストリームの中で重複している行を調べ 、重複している 行は1行にまとめて出力する。 |
| 書式 | uniq [オプション] [入力ファイル名 [出力ファイル名]] |
| オプション | 説明 |
| -d | 重複している行のみ出力。 |
| -u | 重複していない行のみ出力。 |
| -c | それぞれの行が何回現れたかを行の内容とともに表示。 |
——————–
サンプルファイルの作成
viコマンドで「sample2.txt」を作成
[root@localhost ~]# vi sample2.txt [root@localhost ~]# cat sample2.txt 111111 222222 333333 444444 333333 222222 [root@localhost ~]#
——————–
例)連続して重複している行を1行にして表示
「sample2.txt」をソートし、その結果の中で連続して重複している行を1行にして表示。
[root@localhost ~]# sort sample2.txt ★sortのみ確認 111111 222222 222222 333333 333333 444444 ★重複を一行に(一度sortして出力) [root@localhost ~]# sort sample2.txt | uniq 111111 222222 333333 444444 [root@localhost ~]#
——————–
例)連続して重複している行のみを表示
「sample2.txt」をソートし、その結果の中で連続して重複している行のみを表示
★重複している行のみ出力 [root@localhost ~]# sort sample2.txt | uniq -d 222222 333333 [root@localhost ~]#
——————–
例)連続して重複している行を除いて表示
「sample2.txt」をソートし、その結果の中で連続して重複している行を除いて表示。
★重複している行を除いて出力 [root@localhost ~]# sort sample2.txt | uniq -u 111111 444444 [root@localhost ~]#
——————–
まとめ
sort・uniqコマンドしっかりの実行結果をしっかり覚えておきましょう!
それでは今回はこのあたりで。
確認問題
問題1
テキストファイルをソートするコマンドで、正しい選択肢を1つ選びなさい。
A) join
B) paste
C) sort
D) pwd
問題2
ソート済みのファイルから重複した行を削除するコマンドで、正しい選択肢を1つ選びなさい。
A) ls
B) uniq
C) cd
D) cat



