
インデックスとは
本記事からインデックスとは何なのか、どのように使用するのかについて説明していきます。
これまでデータベース上に保存されたデータを検索するには、上から一行ずつ目的のデータを探していました。データ量が少なければこの検索の仕方でも問題ありませんが、データベースには大量のデータが格納されているケースも勿論あります。大量にデータがある場合、上から順に該当するデータがあるか検索する方法は非効率的です。そこで「索引」という機能を利用すると、検索対象となるカラムを探し出してから該当データを読み込むことができるので検索が効率的に行えます。
例えば以下のようなテーブルがあったとします。

名前を検索するとき、データはあ行からわ行まで順番に並んでいないので検索対象のデータを上から順に探すことになります。これくらいのデータ量なら問題ありませんが、何万ものデータが格納されている場合は上から順に検索するのは効率が悪いです。
そんな時にインデックスを利用すると検索スピードが早くなります。インデックスは検索対象のカラムデータを探し出し、ソート(並び替え)することで高速検索できるようにしたものです。
以下の図はインデックスのイメージ図になります。
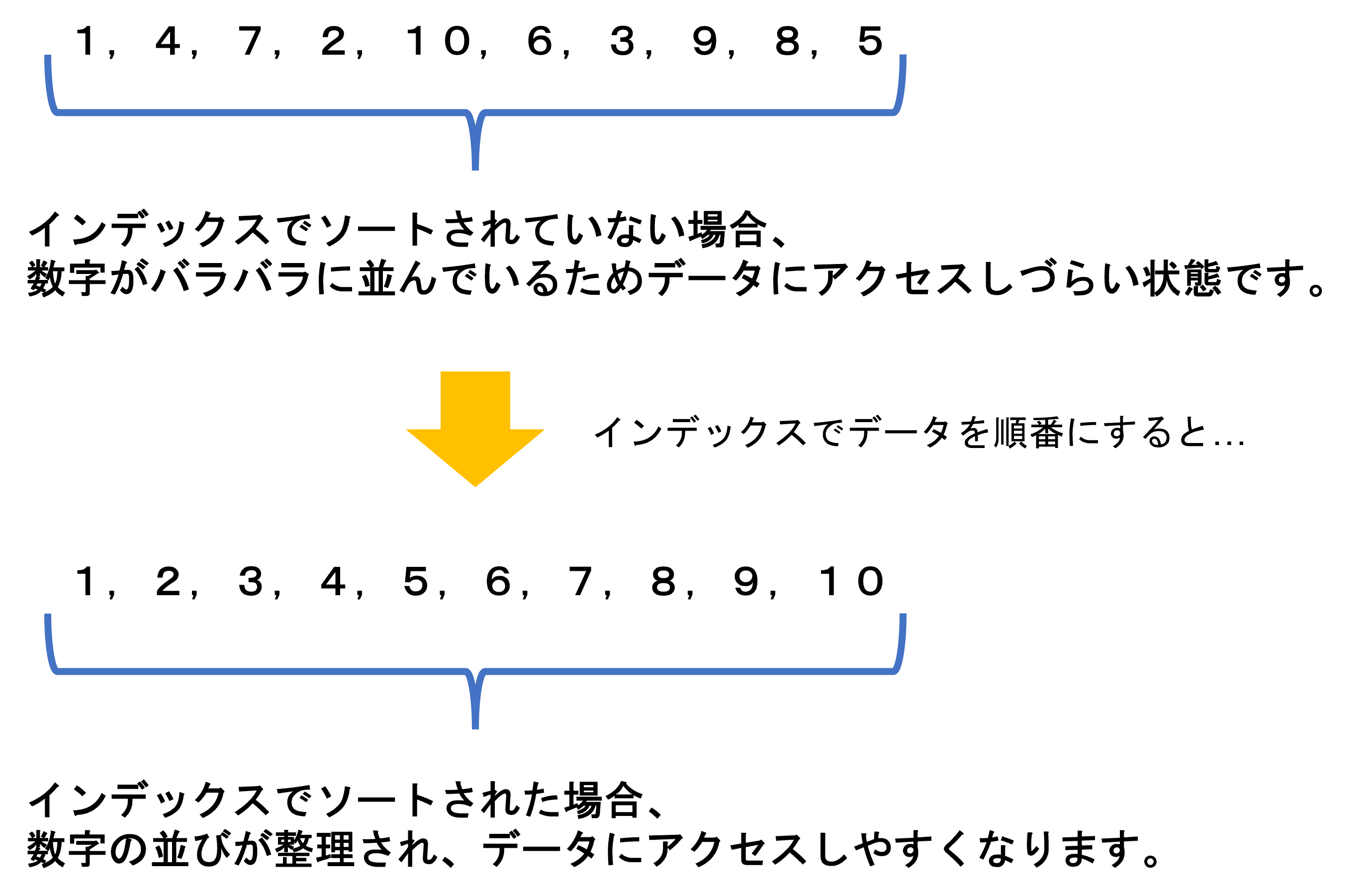
また、同じ値がある場合も効果を発揮します。
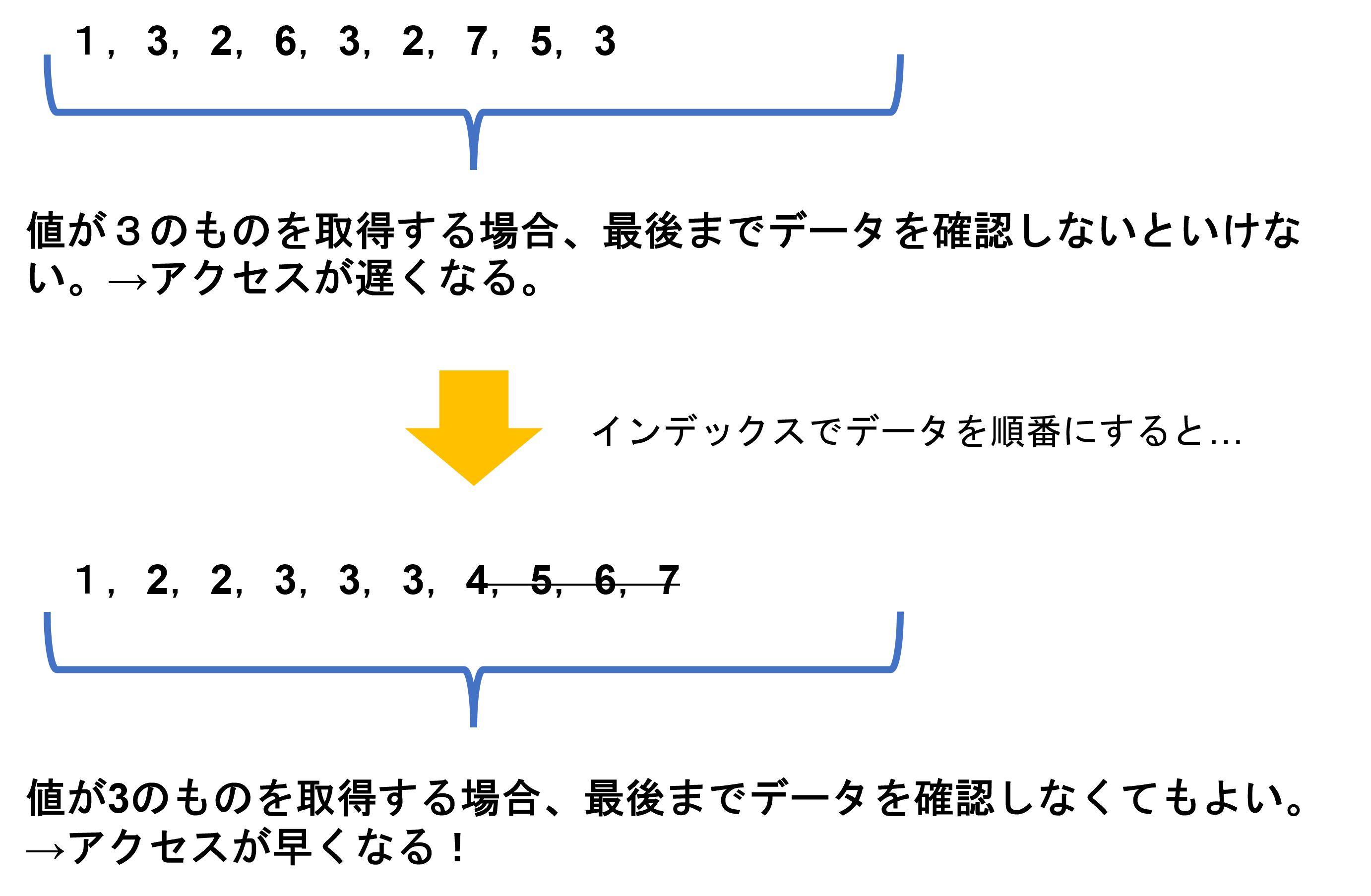
例えば3の値を取得する場合、数字がそろっていない前者だと最後までデータを確認しないと値を取得できません。一方、順番通りにデータが並んでいる後者の場合は左から6番目以降は3がないので最後まで確認しなくても済みます。結果的に取得したいデータへのアクセスが早くなるという訳です。
インデックスの利用条件
[インデックスが利用されるパターン]
・WHERE句でカラム値の絞り込み(WHERE name = ‘シュウタ’)
・WHERE句でカラム値の範囲を指定(WHERE age < 25)
・JOINで結合する(WHERE teachers.name = class.name)
・ORDER BYでの並び替え(ORDER BY age)
・・・・・等。
[インデックスが利用されないパターン]
・算術演算子を使用している(age + 5)
・関数を使用している( AVG(age) )
・ORを使用(WHERE age = 25 OR age = 26)
・・・・・等。
インデックスのメリット&デメリット
[メリット]
パフォーマンス向上
→検索時に高速にデータを取り出せる(特にデータ量が多いとき有効)
[デメリット]
パフォーマンス低下
→テーブルに新規データを追加するとインデックスにも追加されます。また、データの並び替えを行っている場合は、新規データが追加されるたびに並び替えが行われます。新規データを追加すると単純にデータ数が2倍になるので、処理が重くなります。
インデックスを作成する際は、既存のテーブル容量に加えインデックス用のデータ容量が必要になりますので、データベース設計時によく考慮しておきましょう。
インデックスの使い方
これらについては別記事で説明していますので上記リンクをご確認ください。
今回の学習ポイント
・大量にデータがある場合、インデックスを利用することで検索スピードが向上する。
・算術演算子や関数など特定の条件下ではインデックスを作成していても利用できない。
・インデックスは既存のテーブルとは別に保存されるので、データベースの容量と相談しなければならない。
練習問題
- 以下の選択肢からインデックスを使用できるパターンを選択してください。
・算術演算子を使用している
・WHERE句でカラム値の範囲を指定している
・関数を使用している
・JOINで結合している
・ORDER BYで並び替えをしている
以上、インデックスについてでした。
次回は「インデックスの作成」です。


