
目次
gap_buffer<char> + 行管理
gap_buffer<char> は1次元的で、文字位置を0オリジンの数値で指定するが、テキストエディタではテキストを行単位で表示するので、行番号と行先頭位置の高速な相互変換を可能にする必要がある。
特に、スクロールバーをぐりぐりドラッグされた場合を考えると、各行先頭位置を高速に取り出せるようにする必要がある。
そのための最も自然な解決方法は、各行の先頭位置をテーブルで管理する方法だ(下図参照)。
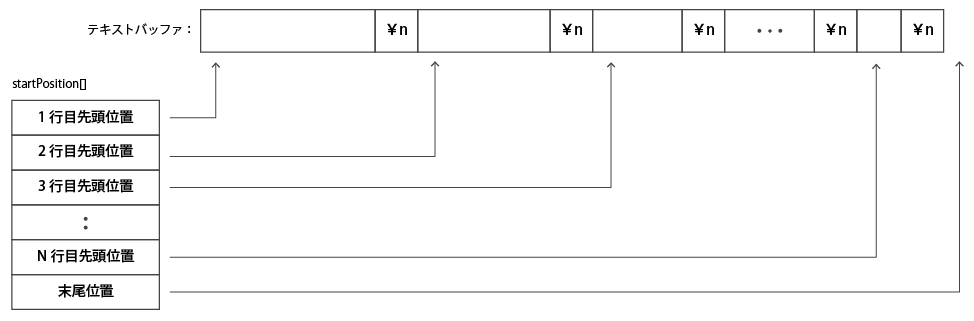
この方法であれば、行番号→行先頭位置変換はテーブルを参照するだけなので、O(1) と高速になる。
また、文字位置→行番号変換も テーブルをバイナリサーチすれば可能なので、O(logN) で計算可能だ。
しかし、この方法には欠点がある。それは、行の長さが変化した場合、当該行~末尾までの位置を更新する必要があり、その処理時間は O(N) となるという点だ。
一括置換などではこの処理を複数回繰り返すので、トータル処理時間が O(N^2) となり、パフォーマンス的に好ましくないのだ。
編集時の更新処理を最小化する解決方法として、各行先頭位置ではなく、各行の長さを保持しておくというものがある(下図参照)。
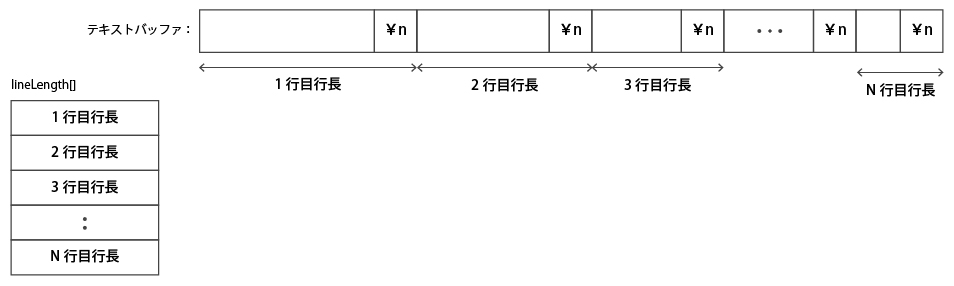
このようにすれば編集時の更新処理は O(1) で済む。
しかし、行の先頭位置を取り出すには、1~L-1 までの行長の総和を求める必要があり O(N) の処理時間を要してしまう。
つまり、行先頭位置・行長テーブル方式は相補的で、どっちもどっちというデータ構造だ。
本連載に何度も出てきた話であるが、テキストエディタにおいては、ほとんどの場合において参照・編集箇所は局所化されているという性質がある。
この性質をうまく利用することで、前者のデータ構造における各行頭位置配列の更新を O(1) に高速化できる。
以下、その具体的アルゴリズムについて解説する。
行先頭位置管理を行うクラスを LineMgr という名前とする。下図にそのクラス図を示す。
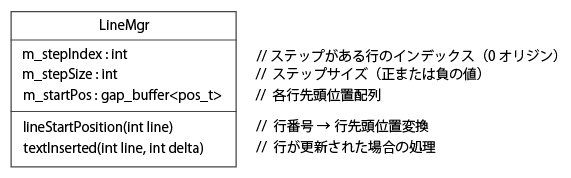
list<string>+キャッシュ の時と同じように、最後に編集された行を m_stepIndex で覚えておき、line == m_stepIndex 行以降(m_stepIndex行も含む)に m_stepSize の差分があるものとする。
つまり、編集箇所が以前の編集箇所と同じ行であれば、m_stepSize を変更するだけで、行先頭位置テーブルの値はいっさい変更しない。
編集を行った行に m_stepIndex があるものとする。なので、m_stepIndex が編集行でない場合は、m_stepIndex を移動し、その間の行先頭位置のみを更新する。
したがって、編集箇所が局所的であれば、その更新処理は少ない行についてのみなので、処理時間は O(1) となる。
このようなアルゴリズムは「遅延評価」と呼ばれる。
行先頭位置情報の更新処理が必要になるまで処理を遅延することで、無駄な処理をはぶき高速化するという手法だ。
以下に、ステップがある場合の、行番号 → 行先頭位置取得処理のコードを示す。
int lineStartPosition(int line) {
return m_startPos(line) + (line > m_stepIndex ? m_stepSize : 0);
}
処理は単純で、行先頭位置をテーブルでひいて、引数で指定された行番号が m_stepIndex より大きければ m_stepSize を加えるだけだ。
次に line 行を編集(挿入・削除)した場合の処理を以下に示す。
void textInserted(int line, int delta) // line 行にdelta文字のテキストが挿入された時の処理
{
if( !m_stepSize ) { // ステップが0の場合
m_stepIndex = line; // ステップ位置を設定
m_stepSize = delta; // ステップを設定
} else { // ステップが0でない場合
if( line != m_stepIndex ) { // ステップ位置と異なる場合
setStepIndex(line); // ステップ位置を line に移動
}
m_stepSize += delta; // ステップサイズ更新
}
}
ステップが0の場合は、なにも処理する必要がなく、m_stepIndex・m_stepSize を引数で渡された値に設定するだけ。
そうでなければ、setStepIndex(line) をコールし、m_stepIndex を line に設定し、m_stepSize を更新する。
以下に setStepIndex(int line) の実装を示す
void setStepIndex(int line) // m_stepIndex を line に設定し、先頭位置テーブルを更新
{
if( line == m_stepIndex ) return; // 変化なしの場合
if( !m_stepSize ) return; // ステップが0の場合は何もする必要がない
if( line > m_stepIndex ) { // ステップ位置より後方に移動する場合
while( line > m_stepIndex ) {
m_startPos[++m_stepIndex] += m_stepSize; // その間の行先頭位置を更新
}
} else { // ステップ位置より前方に移動する場合
while( line < m_stepIndex ) {
m_startPos[m_stepIndex--] -= m_stepSize; // その間の行先頭位置を更新
}
}
}
m_stepIndex を移動する場合は、その行と新しい行までの間の行先頭位置を更新する。
この方法であれば、編集処理毎に行先頭位置情報を最終行まで更新する必要が無く、m_stepIndex を移動する処理は編集箇所が局所的であれば O(1) なので、全体の処理時間は O(N) → O(1) と高速化される。
◎ パフォーマンス測定
100文字*5万~100万行のテキストに対して、各行から1文字削除する処理について、ステップを使う場合・使わない場合で比較を行った。
結果は以下の通り。
各行から1文字削除した場合のテーブル更新処理時間(単位:ミリ秒)
| 種類\行数 | 5万 | 10万 | 20万 | 50万 | 100万 |
|---|---|---|---|---|---|
| 行先頭テーブル | 158 | 502 | 2324 | N/A | N/A |
| 行先頭テーブル+ステップ | 0 | 0 | 0 | 1 | 2 |
単純な行管理では、行数がそう多くない場合は問題となるような処理時間ではないが、数10万行になると無視できないほどの処理時間になる。
対してステップを用いる方法では、100万行になったとしても、処理時間はわずかで、非常に高速なことがわかるはずだ。
関連記事
投稿が見つかりません。
 |
筆者:津田伸秀 プロフィール:テニス・オセロ・ボードゲーム・パズル類が趣味の年齢不詳のおじさん。 自宅研究員(主席)。vi と C++が好き。迷走中・・・ ボードゲーム・パズル系アプリ開発・リリースしてます。 |


