
目次
はじめに
最近、筆者はオープンソース版 ViVi テキストエディタの開発を行っていて
(参照:https://github.com/vivisuke/openViVi)、その実装には様々な種類の実装技術を利用している。
実は前回解説した文字列検索アルゴリズムもそのひとつだった。
それらの中で、今回はテキストエディタの中核とも言える「バッファ」を取り上げる。
「バッファ」を辞書で引くと、[1] 衝撃をやわらげる装置や液 [2] コンピュータで、データを一時的に記憶する場所
と書いてある(Oxford Languagesの定義より)。
テキストエディタにおけるバッファは後者の意味だが、特にテキストデータを保持し、
管理する部分を単に「バッファ」と呼ぶ。
本稿ではそのバッファの数種のデータ構造・アルゴリズム解説、およびそれらのパフォーマンスについて比較解説する。
なお、いつものように本稿のソースコードは github(https://github.com/vivisuke/buffer)で公開しているので、参照されたい。
バッファとは
テキストエディタにおいてテキストデータを保持し、管理する部分を「バッファ」と呼ぶ(「テキストバッファ」と呼ぶ場合もある)。
バッファは様々な機能を持つが、以下のバッファに対する処理をプリミティブと呼ぶ。
・文字参照
・文字挿入
・文字削除
・バッファサイズ参照
テキストエディタの機能としては上記以外にも置換・Undo/Redoなどがあるが、
すべてプリミティブ処理の組み合わせで実現できる。
逆に言うと、プリミティブ処理は他の処理で実現することができない。
参照・挿入・削除処理においては、それらの処理対象位置を指定する必要がある。
本稿では0オリジンの数値でそれら位置を指定することとする。
型としては符号付き64ビット整数を pos_t 型として定義し、これを使用する。
別の方式として、行番号・行先頭からのオフセットで指定する方式もある。
単なる数値で指定するのは1次元的指定だが、行番号・オフセットによる指定は2次元的指定とも言える。
スクリーンエディタではテキストを画面に行ごとに表示するので、行番号・オフセットによる指定も必要であり、
バッファが1次元的な場合はアクセスするときに変換する必要がある。
文字は8ビット長の char を用いるものとする。
vector<char>
バッファの最も単純なデータ構造は、改行も含めて全ての文字データを下図のように1次元に並べたものだ。

単なる配列では、文字が増えて予め確保していた領域サイズを超えてしまったときに困ってしまうので、
C++ 標準ライブラリを利用するのであれば、データ領域を動的に確保してくれる vector<char> または string を使用するとよい。
このようなデータ構造は力ずくなデータ構造で、テキストエディタのバッファとしては実用にはならないのだが、
何がどう実用にならないのかをこれから説明する。
実際の vector<char> または string オブジェクトは文字列長情報・確保済みメモリ容量・バッファへのポインタを持つ
(実装依存、下図参照)。
下図に string のデータ構造例を示す。vector<char> の場合もほぼ同様だ。
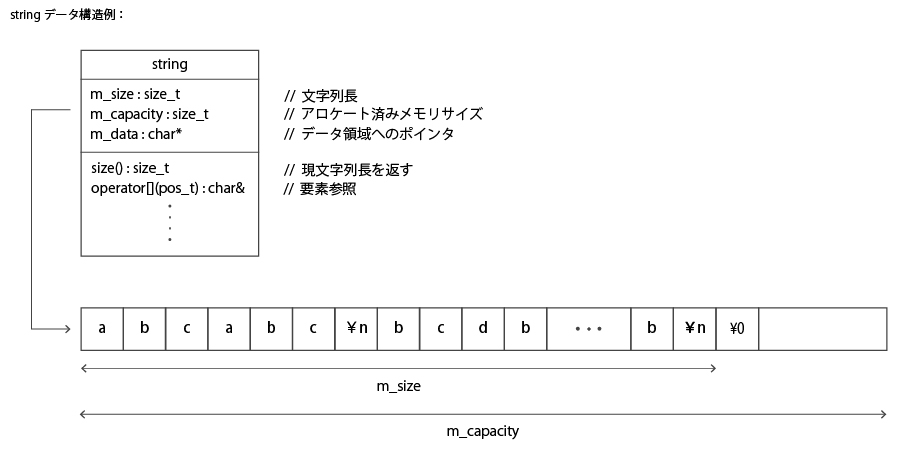
データのための領域は実際のテキスト量よりも多めに確保される。
領域が足りなくなった場合は、データ領域が再アロケートされる。
◎ 実装例
クラス名は my_vector、メンバ変数は前節の通りとする。
実装全体は、https://github.com/vivisuke/buffer/blob/master/buffer/my_vector.h を参照。
文字参照は operator[](size_t) により行う。
char& my_vector::operator[](pos_t pos)
{
return m_data[pos]; // operator[] は pos の範囲チェックを行わない
}
データ領域へのポインタに配列演算子を適用するだけだ。
このアドレス計算は定数時間で行われるので、処理時間は O(1) となり、非常に高速だ。
下記に1文字挿入関数 insert(pos_t, char) のコード例を示す。
void my_vector::insert(pos_t pos, char ch)
{
if( pos > size() ) return; // 挿入位置不正
if( capacity() == size() ) reserve(size() * 2); // 領域が足りない場合は、再アロケート
if( pos < size() ) // 挿入位置以降に文字がある場合
memmove((void*)(m_data+pos+1), (void*)(m_data+pos), (size()-pos)*sizeof(char));
++m_size;
m_data[pos] = ch;
}
データ領域が足りない場合は、メモリを確保し直し、内容を移動する。
指定位置以降を memmove() をコールして末尾から1文字順に後ろにずらし、最後に文字を設定する。
memmove() はC/C++が用意しているメモリコピー関数で、移動元・先が重なっていてる場合にも対応しているものだ。
この処理時間は移動するメモリのバイト数に比例するので、
データが巨大でバッファの先頭付近に挿入するとかなりの処理時間を要してしまう。
reserve() はデータ領域を確保し直し、現データをコピーする関数。
実装コードは省略するので、コードを読みたい方は github を参照されたい。
処理時間はテキストサイズに比例するので O(N) となる。
下記に1文字削除関数 erase(pos_t) のコード例を示す。
void my_vector::erase(pos_t pos)
{
if( pos >= size() ) return; // 削除位置不正
if( pos < size() - 1 ) // 削除位置以降に文字がある場合
memmove((void*)(m_data+pos), (void*)(m_data+pos+1), (size()-pos-1)*sizeof(char));
--m_size;
}
処理は、memmove指定位置から先を1文字分前にずらすだけだ。
削除も挿入と同様に、memmove() の処理時間が移動するメモリのバイト数に比例するので、
データが巨大でバッファの先頭付近の文字を削除するとかなりの処理時間を要してしまう。
処理時間はテキストサイズに比例するので O(N) となる。
まとめると、参照は O(1) で高速だが、挿入・削除は O(N) と低速。
通常は処理時間 O(N*log(N)) まで許されるので O(N) は低速ではないのではないかと思われるかもしれないが、
置換処理などを行う場合、処理回数がNに比例することが多いので、トータルの処理時間が O(N^2) となってしまう。
以上は、1次元のみの場合だが、行・オフセットで編集位置を指定可能にするためには、
vector<pos_t> lineStartPos; などで行管理を行う。
この場合、各行の先頭位置を配列で管理するわけだが、これの高速な更新方法は【第4回】で解説する
◎ パフォーマンス測定:
前節で実装した my_vector を使って、文字参照・挿入・削除処理時間を計測する。
文字参照時間計測結果を以下に示す。
全文字を参照、100~500メガ文字の場合
※ サイズ:メガ文字、処理時間:ミリ秒
| 種類\文字数(メガ) | 100 | 200 | 300 | 400 | 500 |
|---|---|---|---|---|---|
| array[] | 125 | 276 | 452 | 599 | 735 |
| my_vector | 123 | 287 | 409 | 623 | 751 |
my_vector の全要素を [] 演算子で参照する場合を計測した。
比較のために new したメモリに対する場合も計測した。
配列サイズは 100メガ、200メガ、… 500メガ文字とした。
my_vector::operator[](int) の速度は、通常配列処理と大差なく、処理時間は要素数に比例していることがわかる。
ひとつの要素参照は O(1) だが、それをN回繰り返すので、全体では O(N) になっている。
末尾に文字挿入を繰り返した場合の書時間計測結果を以下に示す。
末尾に文字を 20~200メガ文字挿入
※ サイズ:メガ文字、処理時間:ミリ秒
| 種類\文字数(メガ) | 20 | 40 | 60 | 80 | 100 | 120 | 140 | 160 | 180 | 200 |
|---|---|---|---|---|---|---|---|---|---|---|
| std::vector | 111 | 227 | 342 | 445 | 639 | 753 | 833 | 879 | 997 | 1194 |
| my_vector | 109 | 213 | 312 | 425 | 528 | 678 | 777 | 872 | 972 | 1051 |
末尾に文字を 20~200メガ文字挿入する場合の処理時間を計測した。
比較のために std::vector<char> を用いた場合も計測している。
末尾挿入の処理時間は O(1) であり、この計測ではそれをN回繰り返しているので、全体の処理時間は O(N) となっている。
先頭に文字挿入を繰り返した場合の処理時間計測結果を以下に示す。
先頭に文字を 20~200キロ文字挿入
※ サイズ:キロ文字、処理時間:ミリ秒
| 種類\文字数(キロ) | 20 | 40 | 60 | 80 | 100 | 120 | 140 | 160 | 180 | 200 |
|---|---|---|---|---|---|---|---|---|---|---|
| std::vector | 5 | 30 | 33 | 59 | 93 | 135 | 183 | 241 | 307 | 372 |
| my_vector | 3 | 13 | 47 | 63 | 91 | 149 | 180 | 235 | 322 | 369 |
先頭に文字を 20~200キロ(Mega でなく Kilo であることに注意)文字挿入する場合の処理時間を計測した。
比較のために std::vector<char> を用いた場合も計測している。
先頭挿入1回の処理時間は O(N) であり、この計測ではそれをN回繰り返しているので、全体の処理時間は O(N*N) となっている。
末尾文字削除、先頭文字削除も計測したが、全体の処理時間は O(N), O(N*N) と、挿入の場合と同様なので、
詳細は省略する。
実際の計測コードは https://github.com/vivisuke/buffer/blob/master/buffer/buffer.cpp を参照されたい。
◎ まとめ
・文字を単純に1次元に並べたバッファは、文字を大量に保持しているとき、
先頭付近での文字・削除の繰り返しが O(N*N) と低速で実用には耐えない。
・これは大量のデータを頻繁に移動する必要があるためである。
関連記事
投稿が見つかりません。
 |
筆者:津田伸秀 プロフィール:テニス・オセロ・ボードゲーム・パズル類が趣味の年齢不詳のおじさん。 自宅研究員(主席)。vi と C++が好き。迷走中・・・ ボードゲーム・パズル系アプリ開発・リリースしてます。 |


