
目次
前回は長い検索パターンで特に高速になるBMH法について解説した。
BM系やKM系は、文字比較を行った結果の情報を有効に使うことで高速化したが、
今回は、筆者の大好きなビット演算を用いて、パイプライン的処理を行うことで高速化を実現した
bitap アルゴリズムというものを解説する。
bitap アルゴリズム
「bitap」とは、状態をビットで表現した状態遷移マシンを使用するアルゴリズムだ。
「状態をビットで表現した状態遷移マシン」なにそれ?と思われる方も少なくないと思うが、
詳しくはすぐ後に解説する。
(※ ちなみに筆者は bitap という言葉は聞いたことなく、bitmap または bit-op(eration) の
間違いではないのか?と思ったのだが、論文にもちゃんと「bitap」と書いてあるので、これで正しいようだ。)
状態をビットで表現するので、複数状態を同時に表現でき、文字ごとの処理をパイプライン的に同時並行処理できる。
また、1文字あたりの処理が、シフト演算・論理演算だけで行うことができ、非常に高速である。
(そのため、bitap は SHIFT_AND アルゴリズムとも呼ばれる)
特徴としては、[1] 処理時間が被検索文字列長のみに依存し、検索文字列長によらないので、処理時間が非常に安定している。
[2] あいまい検索に強く、大文字小文字同一視処理を行っても処理速度が低下しない。
という特徴がある。
また、BM法などと同様に、検索前に検索パターンを前処理し、高速化をはかっている。
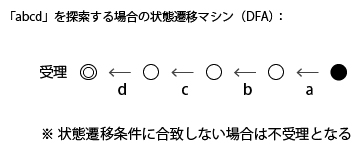
さて、状態遷移マシンとは、下図のように初期状態・途中状態・受理状態、状態遷移条件からなるものだ。
矢印はその部分の文字が入力されるとその先に遷移することを意味する(これを遷移条件と呼ぶ)。
ある状態から遷移不可能な文字が入力された場合は不受理となる。
文字が入力されたときに遷移先が一意に決まるものを「DFA(Deterministic Finite Automaton、決定性有限オートマトン)」と呼ぶ。
一般的には状態が一列に並んでいるとは限らないのだが、単純な文字列検索では下図のように
初期状態から受理状態までが一列に並ぶ。
この例の場合は、「abcd」が順に入力されると受理状態となる。
状態をビットで表現するとは、初期状態以外の各状態を1ビットで表し、有効な状態なら1、無効なら0を値とする、という意味だ。
状態をビット値で表したものを「レジスタ」とも呼ぶ。
例えば、上記の状態遷移マシン初期状態のレジスタの値は 0b0000、
「abc」が入力された場合は 0b0000 → 0b0001 → 0b0010 → 0b0100 と変化する。
そして受理状態のビットの値が1になったとき、受理状態となる。
下図に、被検索文字列 “abcabcabc…abcd” に対して “abcd” を検索する場合を示す。
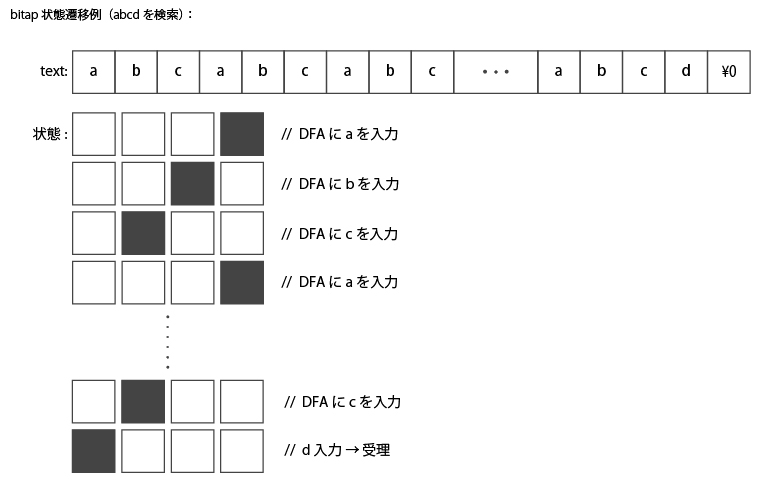
n文字目が入力されて不受理でない場合、レジスタは常に下位からnビット目が1となり、他のビットには干渉しない。
したがって、複数の状態をひとつのレジスタで保持することが可能である。
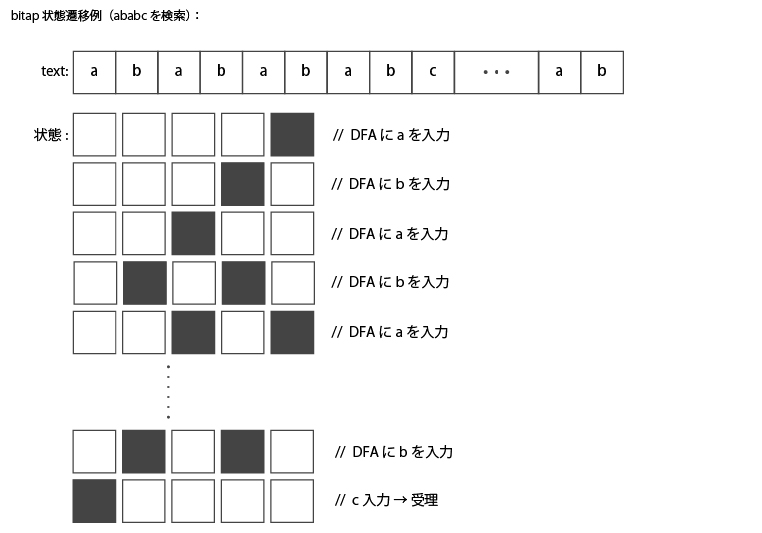
例えば、被検索文字列 “ababab…abcd” からパターン “babc” を検索する場合の、
レジスタの値は以下のようになる。場合によっては、レジスタの複数のビットが立っていることに留意してほしい。
すなわち、状態遷移マシンに順次文字を入力し、受理状態になるか、被検索文字末尾に達するまで、
状態遷移処理を行っていけばよいということだ。
状態遷移処理は比較的軽く、不一致になっても力まかせ探索のような後戻り処理も必要ないので、
検索処理が高速になるという仕組みだ。
bitap も BMH法などのように、検索処理を行う前に検索パターンを前処理し、
遷移可能な状態をビット値としてあらかじめ計算しておく。
その処理は下記のようになる。
typedef const char uchar;
typedef __uint64 Bitmap; // 遷移可能テーブルデータ型
int g_plen; // 検索パターン長
Bitmap g_matchedBit; // 受理状態ビット
Bitmap g_CV[256]; // 文字 0x00 ~ 0xff 遷移可能データテーブル
bool setupBitap(cchar* pat) // 検索文字列から遷移可能テーブル構築
{
g_plen = strlen(pat); // パターン長
if( g_plen > sizeof(Bitmap)*8 ) return false; // パターン長すぎエラー
g_matchedBit = 1 << (g_plen - 1); // 受理状態
for(auto& x: g_CV) x = 0; // 遷移可能テーブルクリア
for(Bitmap m = 1; *pat != '\0'; m<<=1) { // パターンの各文字について
g_CV[(uchar)*pat++] |= m; // *pat の文字が m の位置に遷移可能
}
return true;
}
検索可能な文字列長は状態遷移マシンのビット数が上限となる。
ここでは64ビット変数を用いているので、64文字まで検索可能だ。
検索可能文字列長に上限があるのは bitap の大きな短所だが、実用上は64文字検索できれば十分だと個人的に考える。
※ テキストエディタ等に組み込む場合は、検索パターン長上限を超えた場合は、他のアルゴリズムに自動的に切り替えた方がよいだろう。
m_CV[ch] は、文字 ch で遷移可能な場所のビットパターン(最初の文字が最下位ビット)を示す。 bitap を大文字小文字同一視にするには、状態遷移規則を大文字でも小文字でも可能にするとよい。 したがって、前処理関数は以下のようになる。 検索パターンの各文字の大文字でも小文字でも文字位置に遷移可能なように、g_CV[] を構築するだけだ。 被検索、検索パターンともに ‘a’-‘z’ のランダム、 結果は以下のとおり(環境:Core i7-6700 3GHz, 32GB, Windows 10)。 5文字検索の場合、大文字小文字区別の場合は、strstr2, BMH と同程度 最後に部分一致が発生しまくる最悪ケースの処理時間を見てみよう。 前章で書いたように最悪のケースが出現する確率は極めて低いのだが、 「力まかせ探索」「BMH法」「bitap」の3種類の検索アルゴリズムについて、大文字小文字区別・同一視のそれぞれの場合について解説した 実は大文字小文字を区別する探索では std::strstr() が現状は最も高速(BMH, bitap の通常10倍程度)のようだ。 検索処理は条件により処理速度の優劣が変わってくる。
例えば、検索文字列が “ababc” の場合、’a’ で遷移可能なのは1文字目、3文字目なので、
m_CV[‘a’] の値は 0b00101(0x05)となる。
処理としては、(0オリジン)n文字目が ch だったとき、状態n-1 → n への遷移条件が ch なので、
g_CV[ch] |= (1<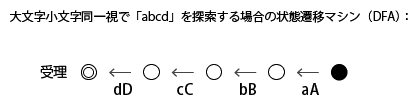
bool setupIcBitap(cchar* pat) // 検索文字列から遷移可能テーブル構築、大文字小文字同一視
{
g_plen = strlen(pat); // パターン長
if( g_plen > sizeof(Bitmap)*8 ) return false; // パターン長すぎエラー
g_matchedBit = 1 << (g_plen - 1); // 受理状態
for(auto& x: g_CV) x = 0; // 遷移可能テーブルクリア
for(Bitmap m = 1; *pat != '\0'; m<<=1) { // パターンの各文字について
uchar ch = *pat++;
g_CV[tolower(ch)] |= m; // *pat の小文字が m の位置に遷移可能
g_CV[toupper(ch)] |= m; // *pat の大文字が m の位置に遷移可能
}
}
そして検索関数は共通(まったく同一)となる。◎ パフォーマンス計測
被検索文字列長は100メガ(1億)で、検索パターンを 10文字、20文字と長くした場合の処理時間を計測してみる。
アルゴリズム
5
10
20
my_strstr
151
102
103
my_strstr2
64
61
79
my_strcasestr
537
577
578
BMH
72
74
27
BMH_IC
88
48
31
bitap
69
69
69
bitap_IC
70
70
70
検索パターン長を長くしても、検索時間には変化が無い。
また、大文字小文字同一視を行っても、処理速度が変化しない。
このように処理時間が非常に安定している。
被検索文字列は100メガバイト長の “aaaaaa…aaZ”、検索パターンは “aaaaZ”, “aaaaaaaaaZ”, “aaaaaaaaaaaaaaaaaaaZ” とする。
アルゴリズム
5
10
20
my_strstr
284
431
921
my_strstr2
742
820
1457
my_strcasestr
2387
4653
10392
BMH
306
305
305
BMH_IC
343
342
341
bitap
70
87
69
bitap_IC
70
69
69
このように部分一致が発生しまくっても、bitap はまったく処理速度が低下せず非常に安定していることがわかる。おわりに
‘a’-‘z’ランダム被検索文字100万文字、検索パターン5文字という条件では、strstr2() が最も高速であったが、
様々な条件により最速なアルゴリズムが替わってしまうのをわかっていただけたと思う。
これを知ったときは非常にびっくりして、その理由を調べてみたのだが、
std::strstr() は、文字列検索に特化した SSE命令を使用しているためだとわかった。
VS2019 ではなぜか std::strcasestr() は提供されておらず、SSE命令は大文字小文字同一視に対応していないか?と思ったのだが、
ある論文には対応していると書いてあったので、そのうち自分でコードを書いて確かめてみたいと思っている。
日本語 UTF-8・UTF-16 や、DNA データに最適化されたアルゴリズムを考えてみるのも面白いかもしれない。
興味ある方はいろいろな条件において最速な検索アルゴリズムの開発にぜひ挑戦してほしい。関連記事
投稿が見つかりません。

筆者:津田伸秀
プロフィール:テニス・オセロ・ボードゲーム・パズル類が趣味の年齢不詳のおじさん。 自宅研究員(主席)。vi と C++が好き。迷走中・・・ ボードゲーム・パズル系アプリ開発・リリースしてます。


