
目次
はじめに
これまではパズル系アルゴリズムについて解説してきたが、今回からちょっと趣向を変えて、
テキストエディタ関連のアルゴリズムについて解説して行きたいと思う。
まずは、3種類の文字列検索(string-search)アルゴリズムについて3回に分けて解説する。
文字列検索とは、プレーンな(通常は長い)文字列から、指定された比較的短い文字列を探し出すことだ。
検索アルゴリズムというと「クイックソートやバブルソートですね」と
言う人が何故か少なくないのだが、それは整列(ソート)であって検索ではない。
(実際、ニコニコ生放送で文字列検索を整列(ソート)と混同している人が2・3人いた)
文字列検索とは以下のように、被検索文字列から指定された文字列
(これを検索パターンと呼ぶ)の場所を探し出すことだ。
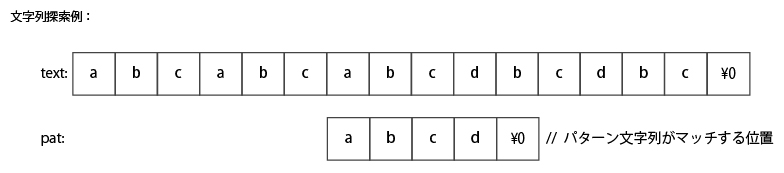
下図に “abcabcabcdbcdbc” から、パターン “abcd” を検索する例を示す。
ブラウザでwebサイトを見ている時に Ctrl + F を押して、検索ボックスに文字列を入力し、
その文字列を探し出すのが文字列検索だ。
また、いわゆるググるのも文字列検索だ。この場合はページ内検索とは違い、
webで公開されている文字列すべてが検索対象となる。
文字列検索はこのように広く使われているものなので、高速化することがとても大事だ。
高速化方法は大別すると以下の2種類がある。
[1] 被検索文字列の前処理を行わず、検索文字列を前処理する(テキストエディタなど)
[2] 被検索文字列を予め前処理しておく(web検索など)
本稿では前者のアルゴリズム、すなわち被検索文字列の前処理を行わないものについて解説する。
最初に最も自然で単純な力まかせ(ブルートフォース)探索について説明し、より高度なアルゴリズムを2つ示す。
文字列のメジャーな表現としては、末尾に番人の ‘\0’ が入っているもの(C/C++ の標準的な文字列表現)と、
その文字列の長を持つ場合の2種類があるが、本稿では基本的に前者を採用する。
(C++ の string クラスは文字列長を保持し、なおかつ末尾には番人の ‘\0’ が入っている)
本稿での、文字列検索関数は、「cchar* my_strstr(cchar* text, cchar* pat)」の形式とする。
ここで、「cchar」は「const char」と定義されているものとする。
また、ブラウザでのページ内検索は英字大文字小文字を同一視した検索が行われることが普通なので、
「cchar* my_strcasestr(cchar* text, cchar* pat)」も解説する。
“abC” と “Abc” を比較する場合は、英字大文字小文字を区別する場合はマッチしないが、同一視の場合はマッチする。
いつものように、本稿の完全なソースは github で公開している。
https://github.com/vivisuke/StringSearch
実際に中身を読んで、ビルド・実行して見たい場合や、一部を修正して実験してみたい方はぜひ参照していただきたい。
以下の参考文献には、本稿で解説するアルゴリズムを含む、38もの検索アルゴリズムが示されている。
・参考文献:
「EXACT STRING MATCHING ALGORITHMS」
http://www-igm.univ-mlv.fr/~lecroq/string/index.html
なぜ、こんなにも多くの検索アルゴリズムが提案されているのかと不思議に思われるかもしれない。
実は各検索アルゴリズムの処理速度はたいてい、N を被検索文字列長とすると、O(N) で大差ないのだが、
被検索文字列・検索文字列の性質、部分マッチの確率により実際の検索時間がかなり変わってくるのだ。
具体的には、DNAの検索に特化したもの、アルファベットの検索に特化したものなどがある。
つまり、条件により最も高速なアルゴリズムが異なってくるために、多くの検索アルゴリズムが提案されているのだ。
力まかせ(ブルートフォース)探索
まずは、最も自然で、誰もがまっさきに思いつくアルゴリズム:「力まかせ(ブルートフォース)探索」から解説しよう。
力まかせ探索アルゴリズムとは、被検索文字列 text の最初から、検索文字列 pat と1文字ずつ比較し、
一致すればその位置を返す、というものだ。
一致しなければ比較開始位置をひとつ先に進め、一致するまで、または text の最後に達するまで繰り返す。
text の最後に到達した場合は nullptr を返す。
なお、ブルートフォース探索アルゴリズムは Naive string-search とも呼ばれているようだ。
(参照:https://en.wikipedia.org/wiki/String-searching_algorithm)
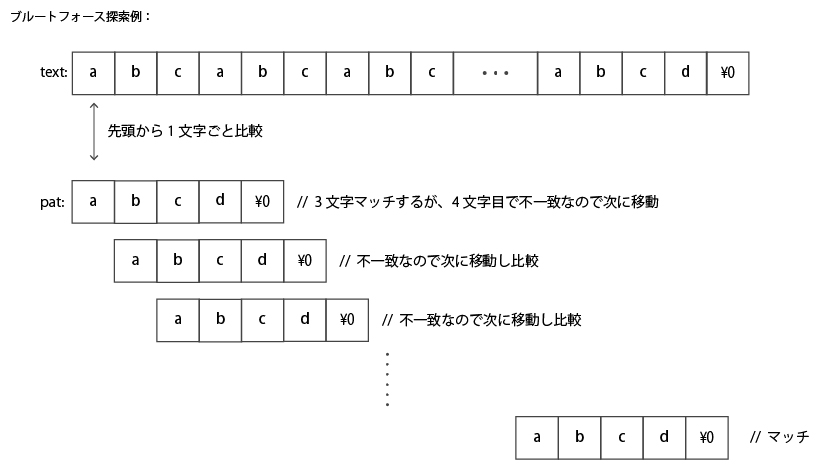
下図にブルートフォース探索の具体例を示す。
◎ strstr() – 大文字小文字区別
ブルートフォース探索による検索関数:my_strstr() は以下のように実装できる。
※接頭辞として「my_」を付けているのは標準関数の std::starstr() と区別するため。
cchar* my_strstr(cchar* text, cchar* pat)
{
while( *text != '\0' ) { // 末尾でない間ループ
if( !my_startsWith(text, pat) ) // text 位置に pat があるかチェック
return text; // あればマッチなので、その場所(text)を返す
++text; // 被検索文字列位置をひとつ進める
}
return nullptr;
}
「while( *text != ‘\0’ )」で被検索文字列の末尾までループし、
my_startsWith() で、テキスト位置の文字列がpatに等しいかをチェックしている。
等しければその位置を返し、被検索文字列の末尾までパターンが見つからなければ nullptr を返している。
非常に単純で素直でわかりやすいコードだ。
my_startsWith()は以下のように実装できる。
bool my_startsWith(cchar* text, cchar* pat)
{
while( *pat != '\0' ) {
if( *pat++ != *text++ ) // ポインタを進めながら、文字が一致するかチェック
return false; // 不一致の場合は false を返す
}
return true; // パターン末尾まで一致した場合は true を返す
}
text と pat を先頭から1文字ずつ比較していき、パターン末尾に達した場合は true を、
途中で不一致文字があった場合は false を返している。
text が pat より短い場合も大丈夫かと心配する人もいるかもしれないが、
text 末尾には番人の ‘\0’ があるので、そこで不一致となり false を返すので大丈夫だ。
以上で、ブルートフォース探索の実装は終わりなのだが、ちょっとしたテクニックで少し高速化しておく。
常にパターンとの文字列比較を行うのではなく、最初に1文字を検索し、
マッチした場合にパターンとの文字列比較を行う方が通常は高速になる。
そのコードを以下に示す。
bool my_startsWith(cchar* text, cchar* pat)
cchar* my_strstr2(cchar* text, cchar* pat) // strchr を使用する版
{
while ((text = strchr(text, pat[0])) != nullptr) {
if( startsWith(text+1, pat+1) ) // text 位置に pat があるかチェック
return text; // あればマッチなので、その場所(text)を返す
++text; // 被検索文字列位置をひとつ進める
}
return nullptr;
}
strchr(text, ch) は、文字列 text に現われる最初の ch の位置を返すC/C++の標準関数だ。
最初の文字を発見したら、(最初の文字は既にマッチしているので)2文字目から比較を行い、
一致すればそのアドレスを返す。
これによりどの程度高速化されるかは、本章末尾のパフォーマンス計測で述べる。
◎ strcasestr() – 大文字小文字同一視
実際の検索では英字の大文字小文字を同一視する場合が多い。
ブラウザでページ内で検索してみるとわかるが、”text” を検索すると “TEXT” にもマッチするはずだ。
というわけで、英字の大文字小文字を同一視する my_strcasestr() の実装も見てみよう。
(大文字小文字同一視検索関数は stristr() とする場合もあるが、なんとなくモダンっぽい気がしたので、
本稿では strcasestr() という関数名を採用させていただいた)
my_strcasestr() の定義は以下のようになる。
bool my_startsWithIc(cchar* text, cchar* pat)
{
while( *pat != '\0' ) {
if( tolower(*pat++) != tolower(*text++) ) // 文字を小文字に変換し、一致するかチェック
return false; // 不一致の場合は false を返す
}
return true; // パターン末尾まで一致した場合は true を返す
}
cchar* my_strcasestr(cchar* text, cchar* pat)
{
while( *text != '\0' ) { // 末尾でない間ループ
if( !my_startsWithIc(text, pat) ) // text 位置に pat があるかチェック
return text; // あればマッチなので、その場所(text)を返す
++text; // 被検索文字列位置をひとつ進める
}
}
大文字小文字を同一視するには、比較のときに文字を大文字に変換し、比較すればよい。
もちろん大文字に変換して比較してもよい。
ちなみに、Visual Studio 2019 では、std::strstr() は定義済みだが、
なぜか std::stristr()、std::strcasestr() は定義されていない。
◎ 力まかせ探索処理時間
と、これまで力まかせ探索アルゴリズムによる strstr(), stracasestr() のコードを見てきたわけだが、
ここでそれらの処理時間について解説しておく。
N を被検索文字列長、M を検索文字列長とすると、力まかせ探索アルゴリズムの処理時間は O(N*M) となる。
つまり、被検索文字列長が長ければ長いほど、検索文字列長が長ければ長いほど、それらに比例して処理時間を要する。
実際の処理時間は、各文字が一致する確率は文字の種類などに依存する。
例えば、DNA の塩基は4種類しかないので、DNA検索は部分マッチしてしまう確率が高く、その分処理時間が長めになる。
最悪なのは、常に途中までマッチしてしまう場合だ。
具体的には、被検索文字列:「aaaaaaaaaaaa…aaaZ」に対して「aaaZ」を検索するような場合だ。
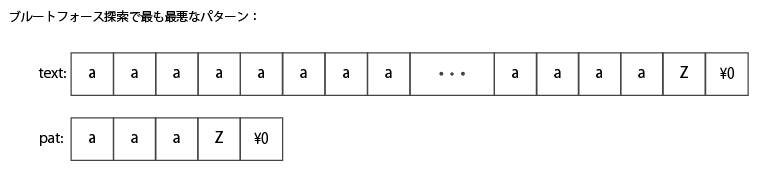
このような場合では、常にパターン長-1 までマッチしてしまい、不一致で次の文字に進むまでに時間を要してしまう。
被検索文字列長を N、検索パターン長を M とするとき、処理時間は O(N*M)となる。
◎ パフォーマンス計測
検索処理時間は被検索文字列・検索文字列の状態によって大きく変わってくる。
まずは、半角小文字 a-z ランダム1億(100メガバイト)の文字列に対して、’a’ – ‘z’ ランダム5文字列を検索する。
マッチしたら次の位置から検索を行い、被検索文字列の最後に達するまでの時間を計測する
計測結果は以下の通り(環境:Core i7-6700 3GHz, 32GB, Windows 10)。
※ランダム1億文字からランダム5文字を検索に要した時間(単位ミリ秒):
| アルゴリズム | 処理時間 |
|---|---|
| my_strstr | 151 |
| my_strstr2 | 64 |
| my_strcasestr | 537 |
strchr() 使用版は、それを使わない my_strstr() に比べて2倍以上高速になった。
大文字小文字を同一視する版は my_strstr() に比べて3.5倍ほど遅くなった。
大文字小文字同一視処理が予想以上に重くてびっくりだ。
違いは大文字または小文字に変換して比較しているだけなのだが、単純な処理の繰り返しなので、
こういうちょっとした処理の追加が全体の処理時間に大きく影響するようだ。
次に、検索パターンはそのままに、被検索文字列長を、2億, 5億にした場合の処理時間を計測してみる。
ランダム1億文字からランダム5文字を検索に要した時間(単位ミリ秒):
| アルゴリズム | 1億 | 2億 | 5億 |
|---|---|---|---|
| my_strstr | 151 | 301 | 766 |
| my_strstr2 | 64 | 124 | 308 |
| my_strcasestr | 537 | 1068 | 2683 |
処理時間がほぼ被検索文字列長に比例しているのがわかる。
次に、被検索文字列長は100メガ(1億)固定で、検索パターンを 10文字、20文字と長くした場合の処理時間を計測してみる。
検索パターン長を長くした場合の検索に要した時間(単位ミリ秒):
| アルゴリズム | 5 | 10 | 20 |
|---|---|---|---|
| my_strstr | 151 | 102 | 103 |
| my_strstr2 | 64 | 61 | 79 |
| my_strcasestr | 537 | 577 | 578 |
現在の条件では部分一致する確率が低く(1文字一致確率は 1/26、2文字連続して一致する確率は 1/676)、
検索パターン長を長くしても検索に要する時間はほとんど変化しないことがわかる。
では、最後に部分一致が発生しまくる最悪ケースの処理時間を見てみよう。
被検索文字列は100メガバイト長の “aaaaaa…aaZ”、検索パターンは “aaaaZ”, “aaaaaaaaaZ”, “aaaaaaaaaaaaaaaaaaaZ” とする。
最悪ケースで、検索パターン長を長くした場合の検索に要した時間(単位ミリ秒):
| アルゴリズム | 5 | 10 | 20 |
|---|---|---|---|
| my_strstr | 284 | 431 | 921 |
| my_strstr2 | 742 | 820 | 1457 |
| my_strcasestr | 2387 | 4653 | 10392 |
最悪のケースではランダムなケースよりかなり遅く、なおかつ検索パターン長に比例して処理時間を要するのがわかる。
とはいっても、このような(文字通り)作ったような最悪ケースが現れることは通常ほぼ無いので、
問題にならないと言えば問題にならない。
あと面白いのは最悪ケースでは strchr() を使用する my_strstr2() が my_strstr() より低速になっていることだ。
これは strchr() が常にマッチしてしまうので、関数コールのオーバヘッドが効いているためだと考えられる。
関連記事
投稿が見つかりません。
 |
筆者:津田伸秀 プロフィール:テニス・オセロ・ボードゲーム・パズル類が趣味の年齢不詳のおじさん。 自宅研究員(主席)。vi と C++が好き。迷走中・・・ ボードゲーム・パズル系アプリ開発・リリースしてます。 |


