
目次
list<string>
前章で取り上げたテキスト全体を単に1次元に並べたデータ構造では、
先頭付近での挿入・削除の繰り返しが O(N*N) と低速で、実用上問題があることを説明した。
これは連続するデータが長いために挿入・削除時のデータ移動に時間を要するためである。
したがって、これを解決するにはデータをより小さい単位に分けるとよい。
そうすれば、挿入・削除時のデータ移動量が膨大にならず、処理時間が高速になる。
具体的には、テキストを改行で区切られる行ごとに分け string で保持し、各行を std::list で管理するとよい。
下図に list<string> のデータ構造例を示す
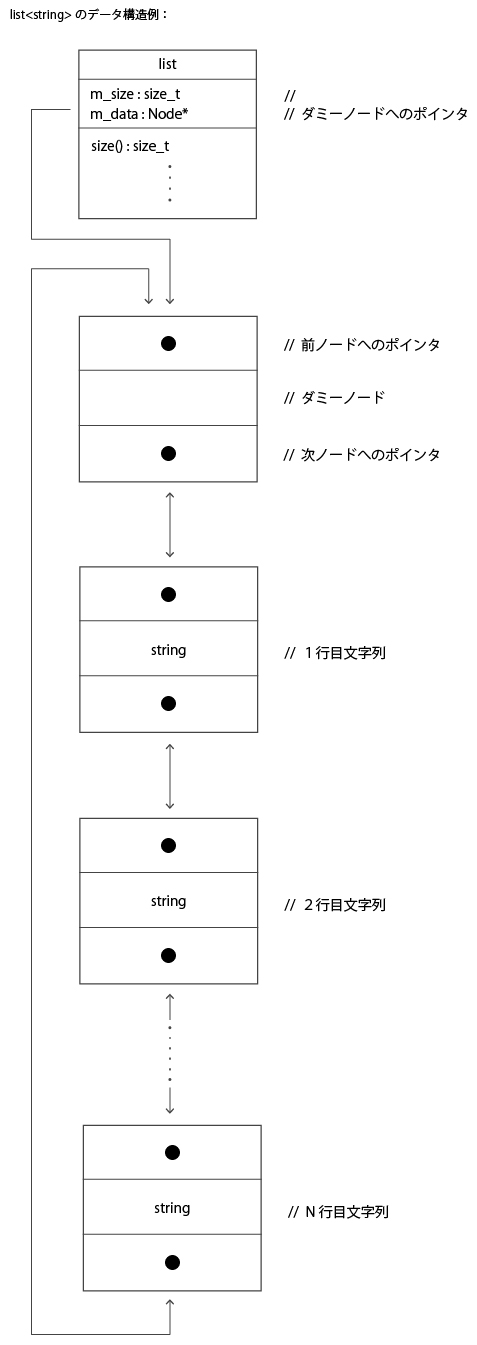
ひとつのデータ単位をノードと呼ぶ。ノードには前後のノードへのポインタと文字列オブジェクトが含まれる。
最初のノードはダミーで、行が1行も存在しない場合でも統一的に扱うためのものだ。
このデータ構造はテキストエディタのバッファとして筆者が最初に学んだものだ。
書籍「Software Tools」Kernighan, Plauger(1976)のテキストエディタにも採用されている。
通常、行はそう長くはならない(1行の長さが千文字を超えることなどめったにないはず)ので、
挿入・削除の処理時間は実質的に O(1)。
vector<char> と違い挿入・削除の処理時間は高速なのだが、
逆に、行番号 → list 要素への変換処理が O(N) の時間を要してしまう。
これは、指定された行番号のノードを見つけるために、先頭ノードから順にノードをたどっていく必要があるからだ。
つまり vector<char> と list<string> は速度性能が相補的とも言える。
参照、挿入・削除の両方の処理速度が純粋に O(1) のデータ構造は存在しないのだ。
◎ 参照・挿入・削除実装例
class StringList が list<string> の派生クラスの場合の実装例を示す。
まずは、文字参照関数 charAt(l, o) の実装例を以下に示す。
char StringList::charAt(int l, int o) {
auto itr = g_list.begin();
while (l > 0) { ++itr; --l; } // 行lまで移動
return (*itr)[o];
}
l行目、o番目(両方とも0オリジン)の文字の参照を返す。
最初の2行で、行番号に対応するイテレータを探し、その string の o 番目の文字の参照を返しているだけだ。
次に文字挿入関数 insertCharAt(int l, int o, char ch) の実装例を以下に示す。
void StringList::insertCharAt(int l, int o, char ch) {
auto itr = g_list.begin();
while (l > 0) { ++itr; --l; } // 行lまで移動
itr->insert(itr->begin() + o, ch);
}
行番号に対応するイテレータを探すのは同様で、それが見つかれば string::insert() を呼んでいるだけだ。
削除のコードは挿入とほとんど同じなので省略する。違いは insert() ではなく erase() を使うだけだ。
◎ パフォーマンス測定:
5文字ごとに1文字挿入を最後まで繰り返えした場合の処理時間計測結果を以下に示す。
行長は80文字で、list<string> は20キロ~200キロ行について計測した。
比較対象として vector<char> でも同様の計測を行ったが、あまりに遅いので行数は100~1000行とした。
| 種類\行数 | 100 | 200 | 300 | 400 | 500 | 600 | 700 | 800 | 900 | 1000 |
|---|---|---|---|---|---|---|---|---|---|---|
| vector<char> | 0 | 5 | 27 | 40 | 57 | 102 | 230 | 515 | 1045 | 2086 |
| 種類\行数(キロ) | 20 | 40 | 60 | 80 | 100 | 120 | 140 | 160 | 180 | 200 |
|---|---|---|---|---|---|---|---|---|---|---|
| list<string> | 3 | 9 | 17 | 49 | 66 | 95 | 102 | 162 | 231 | 257 |
結果は上記の通りで、連続挿入に要する時間は vector<char> は O(N*N)、list<string> は O(N) であることがわかる。
しかも後者の方が圧倒的に高速だ。
◎ まとめ
・文字列を list で管理するバッファは、ひとつの編集処理はおおむね O(1) と高速である。
・が、行番号→ノードを探す処理に時間がかかり、文字参照が O(N) となる。
・この特徴は vector<char> と逆で、相補的と言える。
list<string> + 行番号キャッシュ
筆者は 1997 年に ViVi というテキストエディタを開発開始したのだが、そのときに利用していたのが
list<string> と同等のデータ構造・クラスだった。
当時は MFC というクラスライブラリを使っていたので CList<CVSListBody, CVSListBody&> で行を管理していた。
CList には FindIndex(int) というメンバ関数が用意されていて、
MS が予め用意しているので、これは高速な関数に違いないと思い込み、
FindIndex(int) を使って行番号からノードへのポインタ変換を行っていた。
のだが、数千行くらいのファイルを開いて、スクロールバーで激しく上下スクロールすると、表示が追いつかなくなった。
調べてみると、スクロール位置から画面最上行の行番号を求め、FindIndex(行番号) を呼んでる部分がクリティカルだとわかった。
FindIndex(int) の処理時間が O(N) のため、行数が多くなると実用に耐えなかったのだ。
うーんと数10分間悩んで考えついたのが、以前にアクセスされた行番号とそれに対応するノードを覚えておき、
新たに与えられた行番号がそれに近いときは、そこからたどっていけばいいやん、というアルゴリズムだ。
筆者はこれを「行番号キャッシュ法」と呼んでいた。
なお、これがすでに提案済みのアルゴリズムかどうかは調べていないのでわからない。
なぜこの方法により高速化されるのかと言うと、実はテキストエディタにおいてはテキストの参照・編集箇所は局所化されている、
という性質があるからだ(局所的編集とは直前編集箇所と次の編集箇所がそう離れていないという意味)。
単に画面にテキストを表示する場合でも、画面最上行から1行ごとに次の行に移り最終行までを参照する。
編集箇所も多くの場合は1画面内であり、毎回遠く離れた場所を編集することは稀だからだ。
◎ 実装例
以下に、キャッシュされている情報を使って、行番号→ノードの変換を行う関数:findIteratorCached(line) のコードを示す。
完全なソースは https://github.com/vivisuke/buffer/blob/master/buffer/StringList.h を参照。
StringList::iterator findIteratorCached(int line)
{
if( line < 0 || line >= size() ) return end();
if( m_cachedLine < 0 ) { // キャッシュが無い場合
return m_cachedItr = findIndex(m_cachedLine = line);
}
if( line == m_cachedLine ) // キャッシュ行番号と同じ場合
return m_cachedItr;
if( line < m_cachedLine ) { // キャッシュ行番号より前の場合
if( line >= m_cachedLine / 2 ) { // キャッシュ行の半分より後ろにある場合
while( line < m_cachedLine ) { // キャッシュ行から前に検索
--m_cachedItr;
--m_cachedLine;
}
} else { // キャッシュ行の半分より前にある場合
m_cachedItr = begin();
m_cachedLine = 0;
while( line < m_cachedLine ) { // キャッシュ行から後ろ検索
++m_cachedItr;
++m_cachedLine;
}
}
} else { // キャッシュ行番号より後ろの場合
.....
}
return m_cachedItr;
覚えている行番号に近ければそこから。そうでなければ先頭または末尾からノードを探しているだけだ。
◎ パフォーマンス測定:
2千行~2万行のテキストに対し、先頭行から末尾行までを参照するのに要する時間を計測してみた。
最初から最後まで行を参照するのに要する時間
※ 行数:キロ行、処理時間:ミリ秒
| 種類\行数(キロ) | 2 | 4 | 6 | 8 | 10 | 12 | 14 | 16 | 18 | 20 |
|---|---|---|---|---|---|---|---|---|---|---|
| findIterator | 4 | 17 | 42 | 83 | 144 | 213 | 303 | 387 | 543 | 804 |
| findIteratorCached | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
計測結果は上記の通りで、単純な順次探索処理は O(N) であることがわかる。
それに対して、キャッシュを用いたアルゴリズムは、それより遥かに高速であることがわかる。
計測結果がすべて1ミリ秒未満なので、行数を100倍した場合も計測してみた。
結果は下記の通りであった。
最初から最後まで行を参照するのに要する時間
※ 行数:キロ行、処理時間:ミリ秒
| 種類\行数(キロ) | 200 | 400 | 600 | 800 | 1000 | 1200 | 1400 | 1600 | 1800 | 2000 |
|---|---|---|---|---|---|---|---|---|---|---|
| findIteratorCached | 2 | 5 | 8 | 11 | 13 | 16 | 19 | 21 | 24 | 22 |
◎ まとめ
・list<string> は編集処理時間はおおむね O(1) であるが、文字参照が O(N) と遅く問題である。
・最後に参照した場所・ノードを覚えておき、その情報を利用することで文字参照を O(1) に高速化できる。
・これは、テキストエディタにおいては文字参照・編集箇所が局所化されているためである。
関連記事
投稿が見つかりません。
 |
筆者:津田伸秀 プロフィール:テニス・オセロ・ボードゲーム・パズル類が趣味の年齢不詳のおじさん。 自宅研究員(主席)。vi と C++が好き。迷走中・・・ ボードゲーム・パズル系アプリ開発・リリースしてます。 |


